Portfolio Details
Identification of Adult Content in Twitter Tweets Using the BiLSTM Model
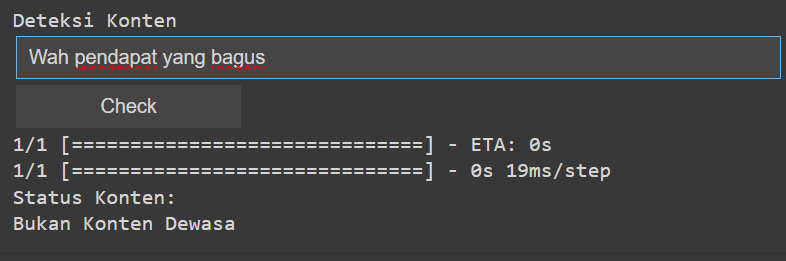
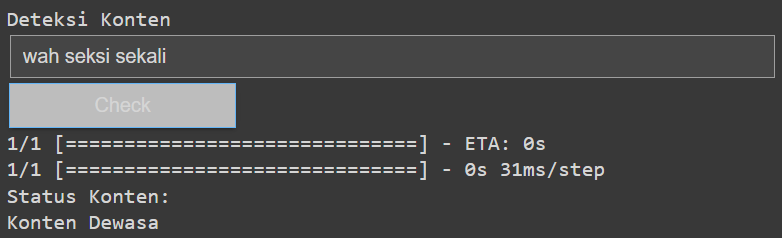
This project aims to develop a sentiment analysis model capable of identifying adult content in Twitter tweets using the BiLSTM model. The primary objective is to classify tweets as either "positive" or "negative" based on their content, with a focus on detecting adult content. This project leverages the power of natural language processing (NLP) and machine learning to analyze the sentiment of tweets and provide insights into the nature of the content. The model was trained on a large dataset of Twitter tweets, which were preprocessed to remove noise and irrelevant information. The BiLSTM model was chosen for its ability to capture long-term dependencies in the data, which is crucial for understanding the context of the tweets. The model was evaluated using various metrics, including accuracy, precision, recall, and F1-score. The results showed that the model was able to effectively classify tweets, with a high accuracy rate.
Process
- Data Collection: The data was obtained through web scraping techniques, specifically by extracting tweets from several Twitter accounts, which provided a comprehensive dataset for further analysis.
- Data Labeling: The data was labeled with the following categories: 1 for "positive" and 0 for "Negative".
- Data Preprocessing: During the preprocessing phase, several steps were taken, including casefolding to convert all text to lowercase, removing numbers, punctuation, and repeated characters, normalizing slang words, and removing common stop words from the text.
- Training Model: The model was trained using the BLSTM (Bidirectional Long Short-Term Memory) algorithm.
- Model Evaluation: The model was evaluated using the Accuracy metric.
Result
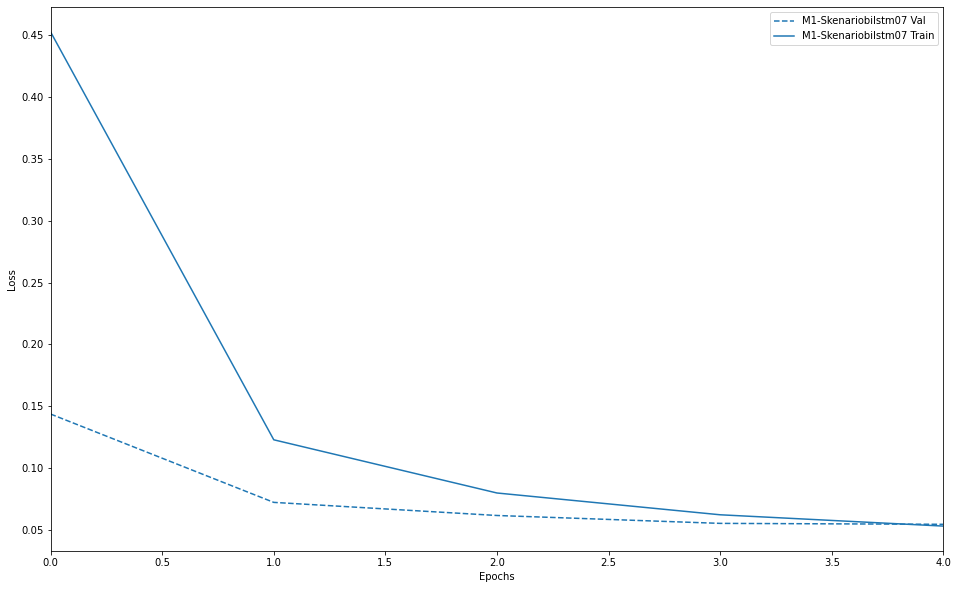
The project successfully implemented sentiment analysis on Twitter tweets using the BiLSTM model to identify adult content. The model was trained on a large dataset of tweets and achieved a high accuracy rate in classifying tweets as either "positive" or "negative". This shows the distribution of positive and negative sentiments across different categories of tweets. From this graph, we can conclude that the model performs well without any indication of overfitting. The loss curve for training and validation decreases similarly, which means the model is able to learn effectively without losing its ability to generalize. The analysis provided valuable insights into the nature of adult content on Twitter, highlighting the importance of implementing effective content moderation strategies to ensure a safer online environment.
Project information
- CategoryData Science
- ToolsPython, Jupyter Notebook, Pandas, Numpy, Matplotlib, Seaborn, Scikit-learn, TensorFlow, Keras
- Project date 26 July 2021
- Project URL https://github.com/RaihanAjah/Adult-Content-Albayanat/tree/main